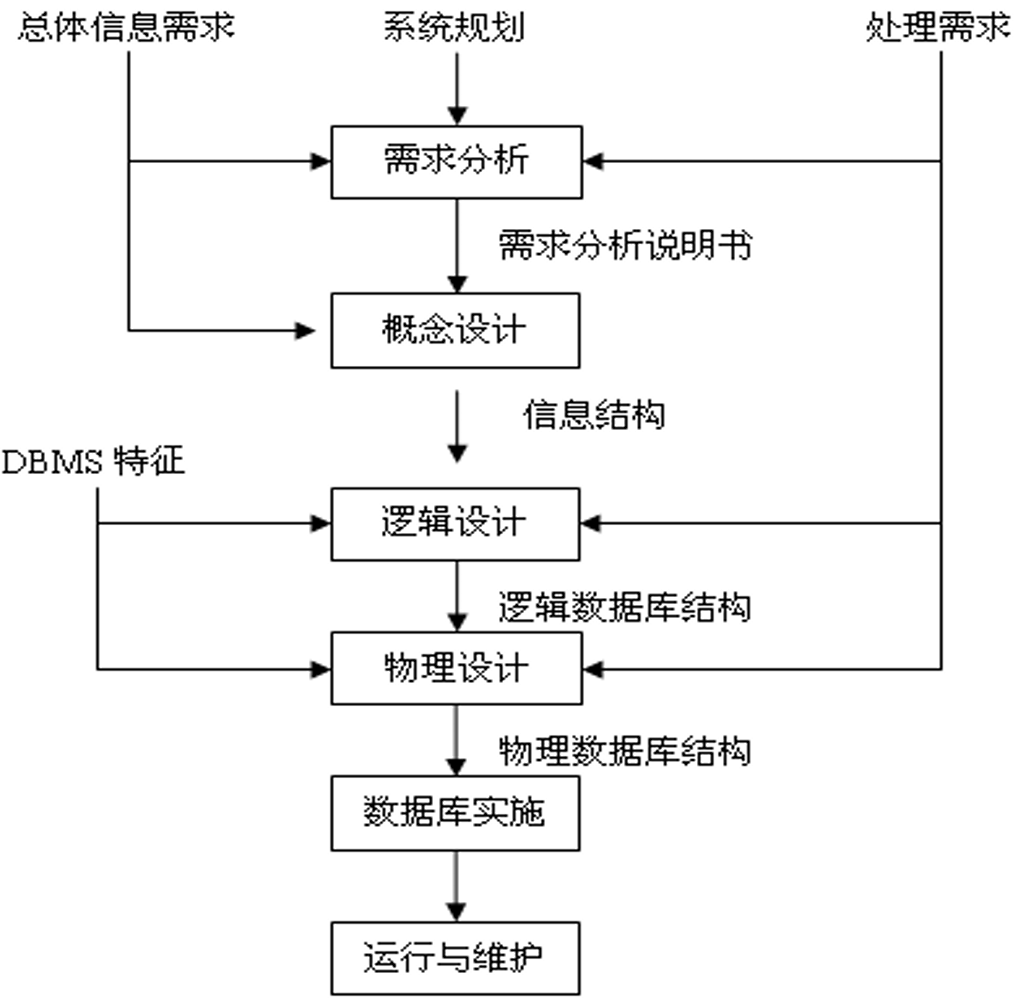
数据库设计
一、设计方法
本课程指定设计方法
- 以新奥尔良方法为基础,基于ER模型和关系模式, 采用计算机辅助进行数据库设计
- 概念设计:基于ER模型
- 逻辑设计:基于关系模式设计
- 计算机辅助设计工具:PowerDesigner(SYBASE)
二、概念设计
产生反映组织信息需求的数据库概念结构, 即概念模型。
- 概念模型独立于数据库逻辑结构、DBMS以及计 算机系统
- 概念模型以一组ER图形式表示
概念设计侧重于数据内容的分析和抽象,以用户的观点描述应用中的实体以及实体间的 联系。
2.1 ER模型要素
实体(Entity) :包含实体属性
- 现实世界中可标识的对象
- 应用中的数据以实体的形式呈现
- 一个实体具有唯一的标识,称为码(Key)
联系(Relationship) :包含联系类型和联系属性
- 实体和实体之间发生的关联
- 一个实体一般都与一个或多个实体相关
- 类型:1对1联系(1 : 1)、1对多联系 (1 : N) 和多对多联系(M : N)
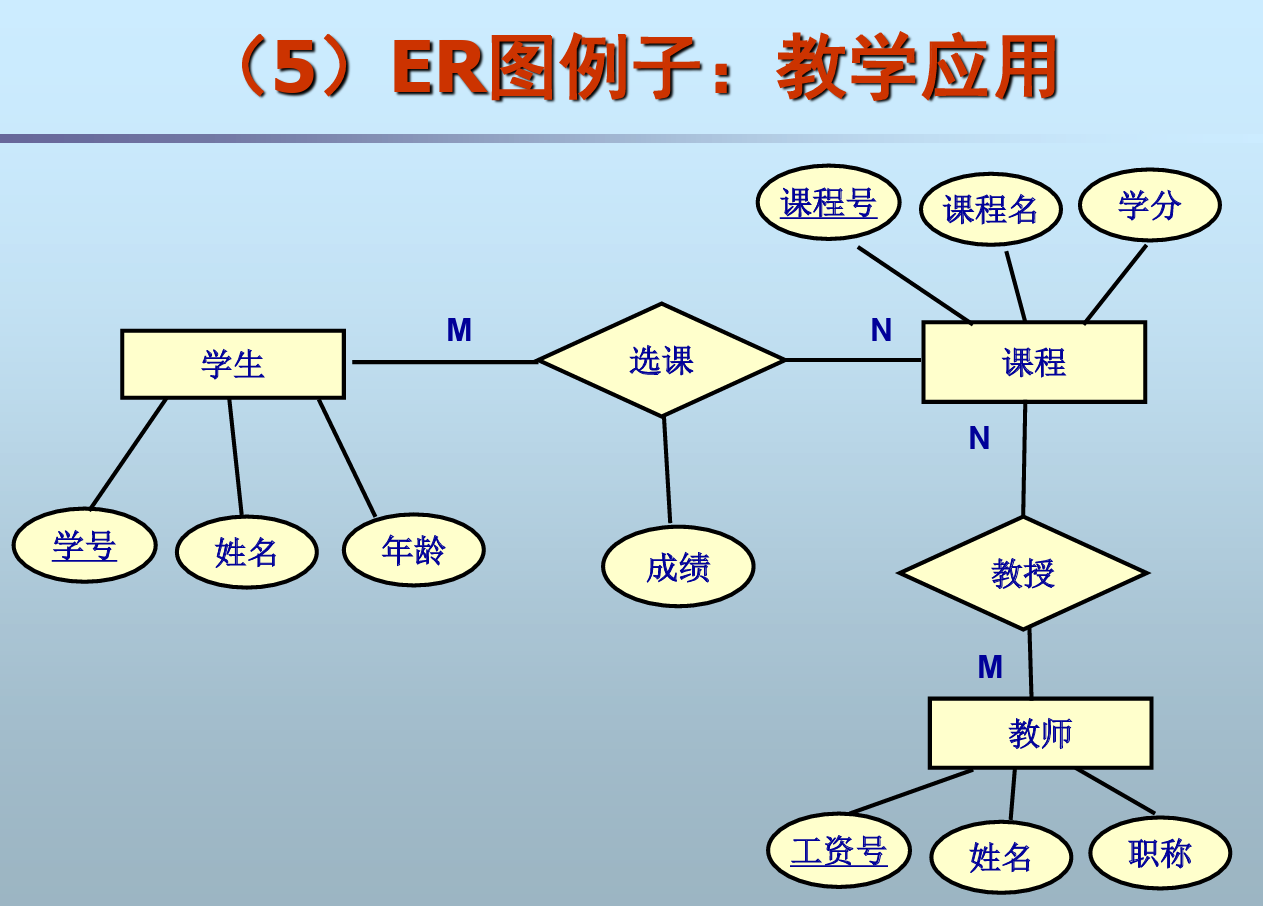
2.2 ER设计步骤
自顶向下进行需求分析,自底向上进行ER设 计
分ER设计
通过实体、联系和属性对子系统的数据进行 抽象,产生分ER图
设计原则
- 实体要尽可能得少
- 现实世界中的事物若能作为属性就尽量作为属性 对待
- 确定实体
- 需求分析阶段产生的数据字典中的数据存储 、数据流和数据结构一般可以确定为实体
- 数据字典五个部分:数据项、数据结构、数据流、数据存储和数据处理
- 确定实体属性
- 首先确定实体的码
- 属性应具有域
- 属性一般要满足下面的准则
- 属性必须不可分,不能包含其它属性
- 属性不能和其它实体具有联系
- 确定联系和联系属性
- 根据数据需求的描述确定
- 确定联系的基数
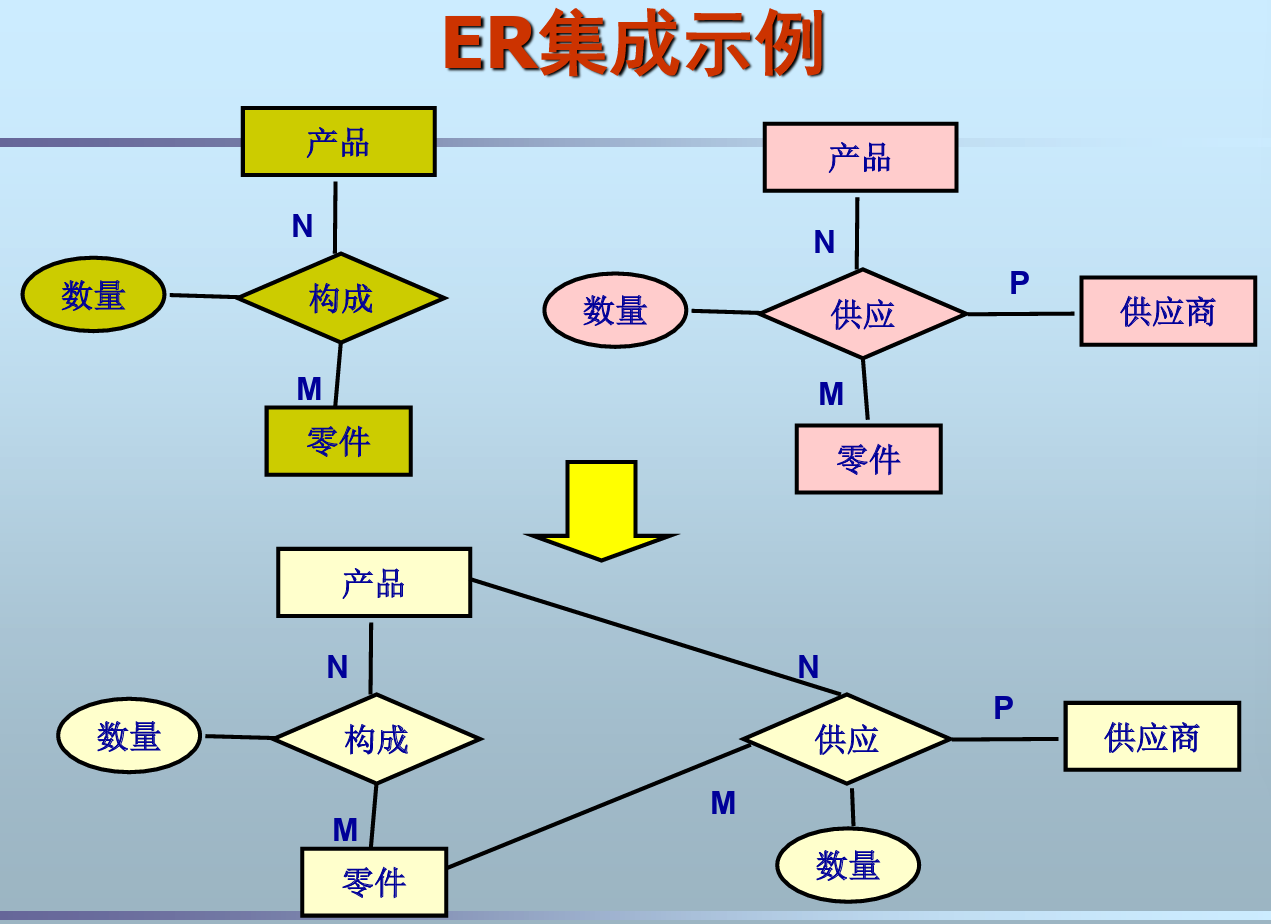
ER集成
- 确定公共实体
- 合并分ER图
- 消除冲突(不是很理解)
- 属性冲突:类型冲突、值冲突
- 例如性别、年龄
- 结构冲突:实体属性集不同、联系类型不同、同 一对象在不同应用中的抽象不同
- 命名冲突:同名异义、异名同义
- 实体命名冲突、属性命名冲突、联系命名冲突
- 属性冲突:类型冲突、值冲突
ER模型优化
目标:实体个数要少,属性要少,联系尽量 无冗余(总的来说就是精简)
合并实体
- 一般1:1联系的两个实体可以合并为一个实体
- 如果两个实体在应用中经常需要同时处理, 也可考虑合并
- 例如病人和病历,如果实际中通常是查看病人时 必然要查看病历,可考虑将病历合并到病人实体 中
- 减少了联接查询开销,提高效率
消除冗余属性
- 分ER图中一般不存在冗余属性,但集成后可 能产生冗余属性(语义一样的属性,描述的是同一个东西)
- 例如,教育统计数据库中,一个分ER图中含有高 校毕业生数、在校学生数,另一个分ER图中含有 招生数、各年级在校学生数 。每个分ER图中没有冗余属性,但集成后“在校学 生数”冗余,应消除
- 冗余属性的几种情形
- 同一非码属性出现在几个实体中
- 一个属性值可从其它属性值中导出 ,例如出生日期和年龄
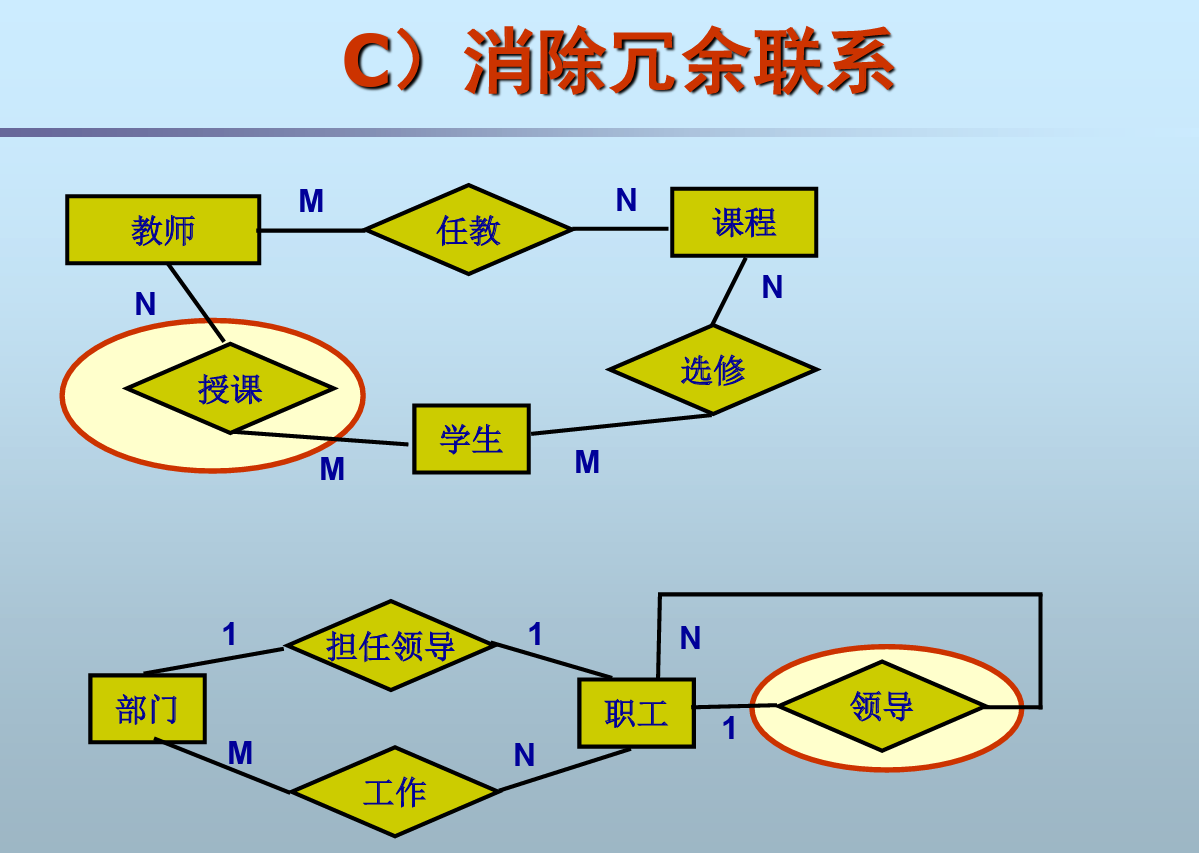
消除冗余联系
有点抽象,大概也是语义重复了就需要消除。
ER模型扩展
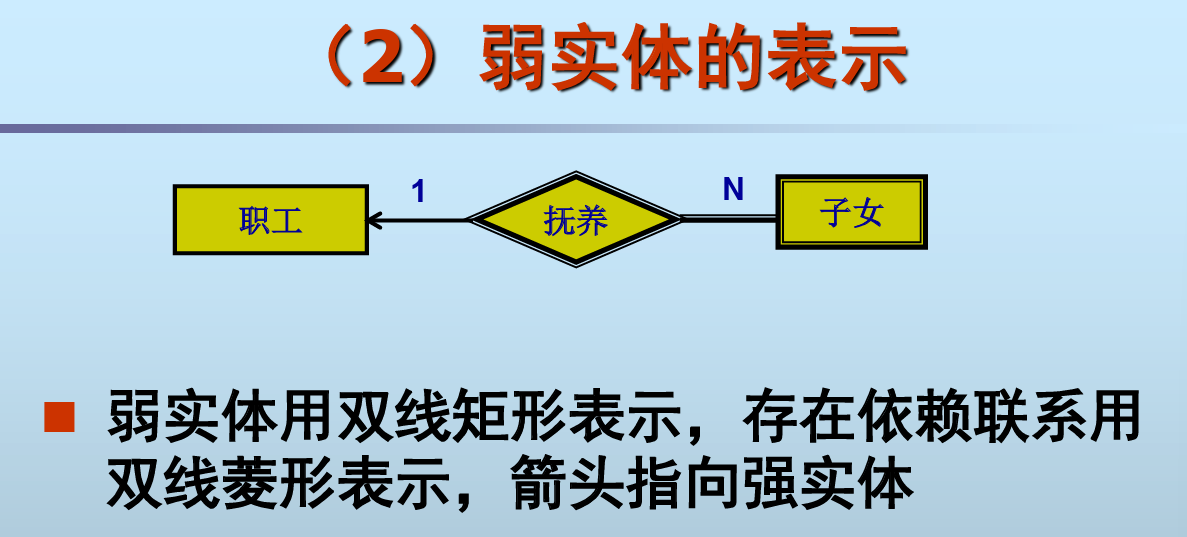
弱实体
一个弱实体的存在必须以另一实体的存在为 前提
- 弱实体所依赖存在的实体称为常规实体(regular entity)或强实体(strong entity)
- 弱实体有自己的标识,但它的标识只保证对于所 依赖的强实体而言是唯一的。在整个系统中没有 自己唯一的实体标识(例如:账户为强实体,转账为弱实体,每一笔转账都有时间作为标识,但仅仅对特定一个账户是唯一的)
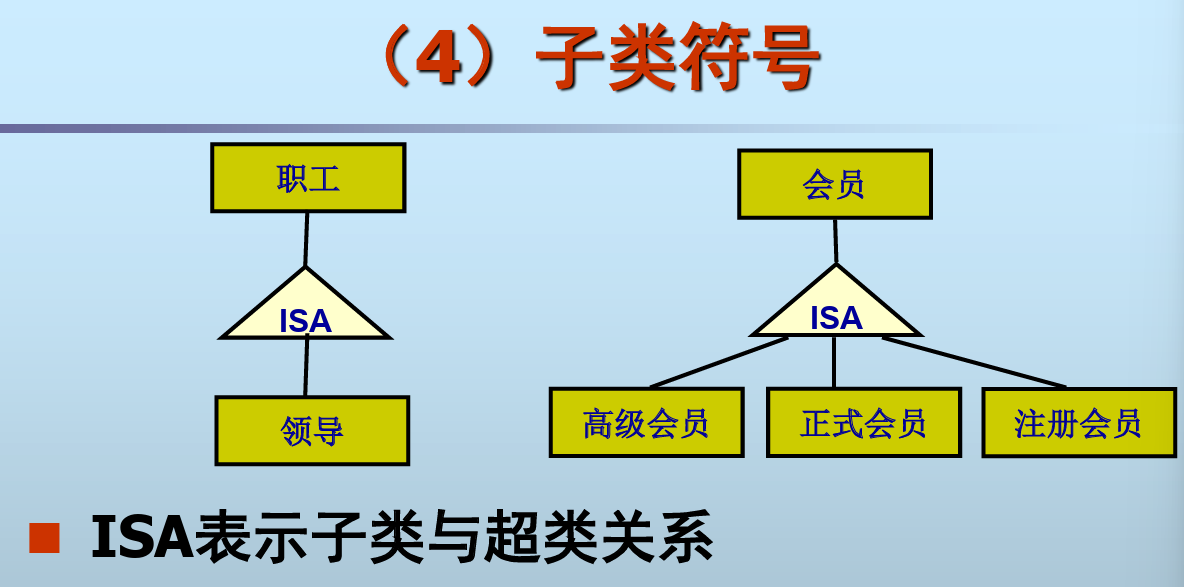
子类(特殊化)和超类(一般化)
- 两个实体A和B并不相同,但实体A属于实体B, 则A称为实体子类,B称为实体超类
- 子类是超类的特殊化,超类是子类的一般化
- 子类继承了超类的全部属性,因此子类的标识就 是超类的标识,子类可以有自己的独有属性
- 例如,研究生是学生的子类,经理是职工的子类
在ER设计时,可以根据实际情况增加子类, 也可以根据若干实体抽象出超类
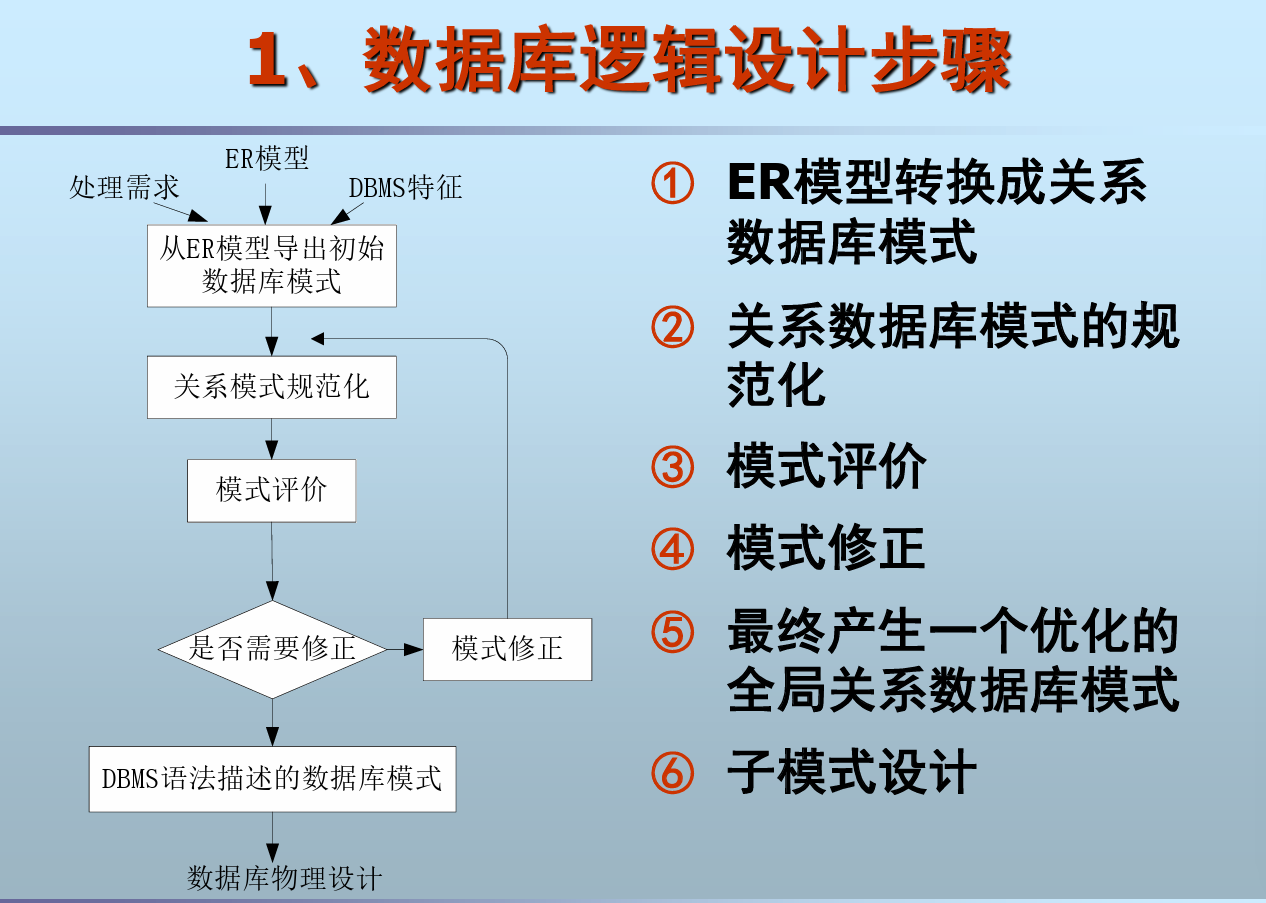
三、逻辑设计
主要内容
根据概念模型设计出与DBMS支持的数据模 型相符合的数据库逻辑结构
- ER模型向关系模型的转换
- 关系模型优化
- 关系模型修正
3.1 基本ER模型的转换
实体转换
- 每个实体转换为一个关系模式
- 实体的属性为关 系模式的属性
- 实体的标识成为关系模式的主码
联系转换
- 1 : 1:将任一端的实体的标识和联系属性加入另一 实体所对应的关系模式中,两模式的主码保持不 变
- 1 : N:将1端实体的标识和联系属性加入N端实体 所对应的关系模式中,两模式的主码不变
- M : N:新建一个关系模式,该模式的属性为两端 实体的标识以及联系的属性,主码为两端关系模 式的主码的组合
3.2 扩展ER模型的转换
弱实体转换
- 每个强实体像一般实体一样转换为一个关系模式
- 每个弱实体转换为一个关系模式,并加入所依赖 的强实体的标识,关系模式的主码为弱实体的标 识加上强实体的标识(账户+转账时间,唯一确定一笔转账)
子类转换
- 父类实体和子类实体都各自转换为关系模式,并 在子类关系模式中加入父类的主码,子类关系模 式的主码设为父类的主码
3.3 模式的规范化
1. 确定范式级别
根据实际应用的需要(处理需求)确定要达到 的范式级别
时间效率和模式设计问题之间的权衡(主要考虑更新操作的多少)
- 范式越高,模式设计问题越少,但连接运算越多, 查询效率越低
- 如果应用对数据只是查询,没有更新操作,则非 BCNF范式也不会带来实际影响
- 如果应用对数据更新操作较频繁,则要考虑高一级 范式以避免数据不一致
- 实际应用中一般以3NF为最高范式
2. 确定范式级别后,进行规范化处理
3.4 模式评价
检查规范化后的数据库模式是否完全满足用 户需求,并确定要修正的部分
- 功能评价:检查数据库模式是否支持用户所有的 功能要求
- 必须包含用户要存取的所有属性
- 如果某个功能涉及多个模式,要保证无损连接性
- 性能评价:检查查询响应时间是否满足规定的需 求。
- 由于模式分解导致连接代价
- 如果不满足,要重新考虑模式分解的适当性
- 可采用模拟的方法评价性能
3.5 模式修正
根据模式评价的结果,对已规范化的数据 库模式进行修改
- 若功能不满足,则要增加关系模式或属性
- 若性能不满足,则要考虑
- 逆规范化
- 分库分表
- 使用存储过程
- 缓存加速
优化策略(提升性能,不是改善功能)
- 逆规范化:模式合并,增加冗余属性
- 分库分表
- 横向切分数据(冷热数据划分)
- 纵向分解模式(其实就是模式分解,常用的属性单独划分为一个模式,或者一些重复值多的属性划分出去)

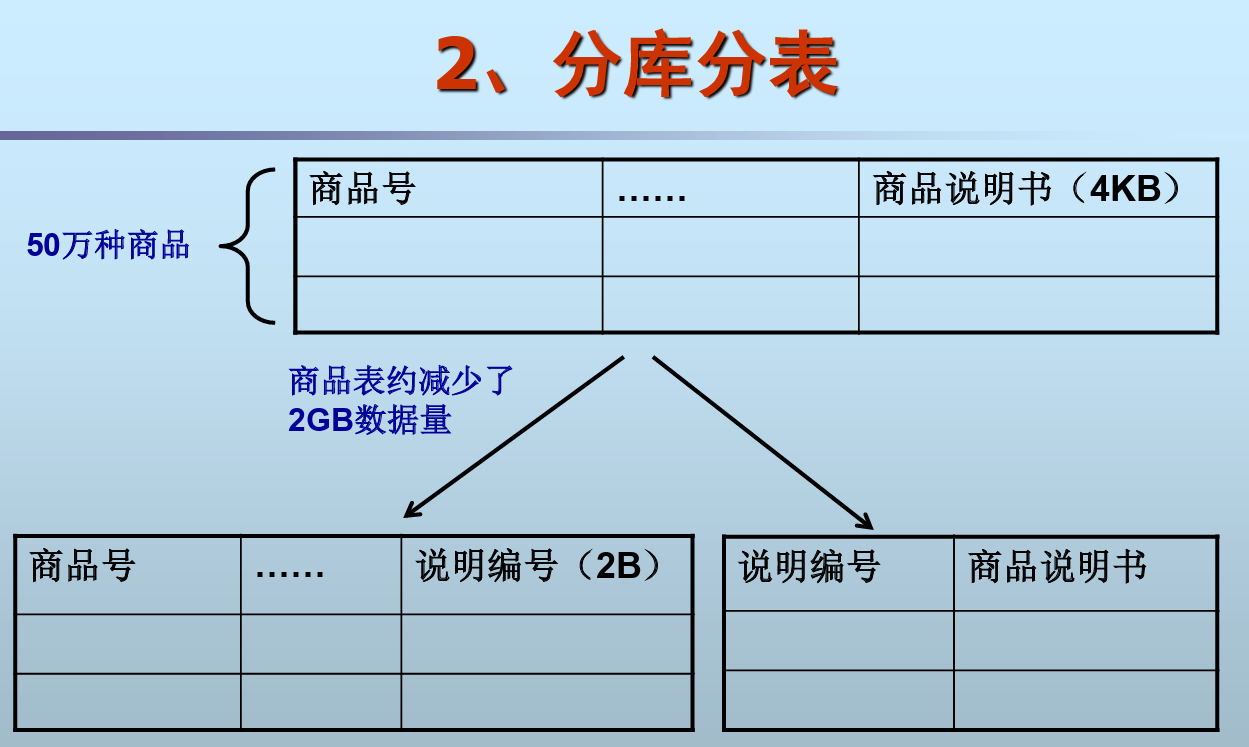
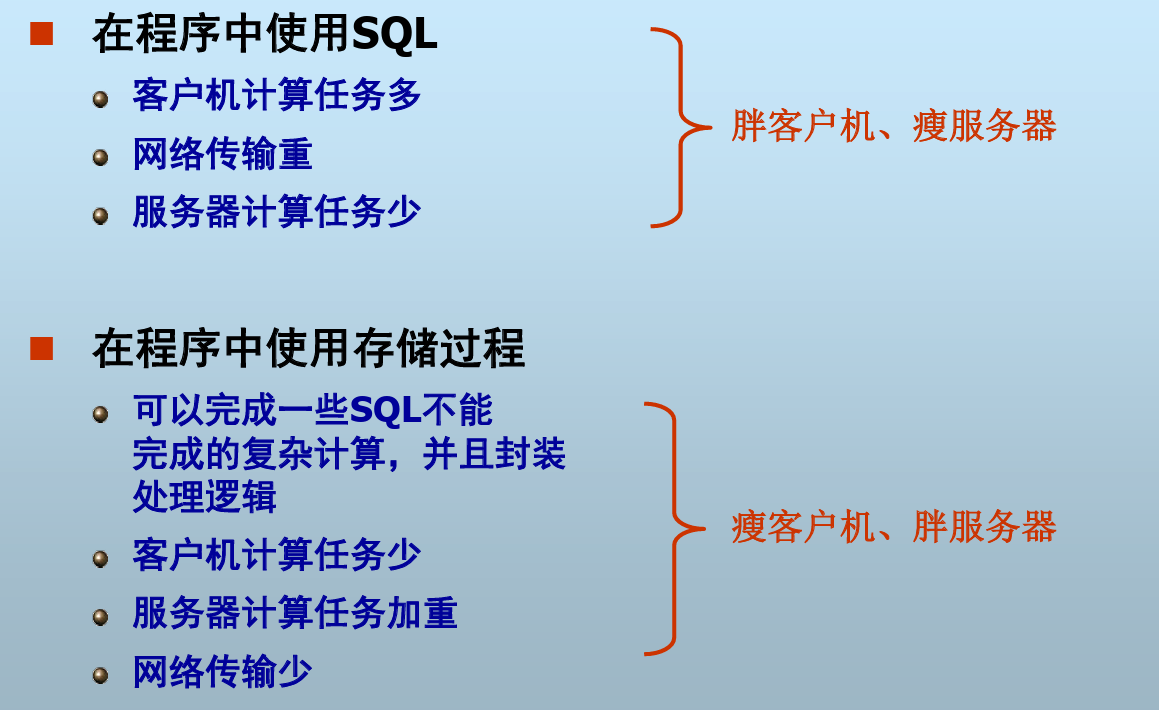
- 使用存储过程
- 客户在服务器上存储一个写好的程序
- 可以在前端程序中调用,将数据密集型任务交给数据库服务 器完成
- 缓存加速
- Redis
- Memached
3.6 设计用户子模式(视图)
- 使用更符合用户习惯的别名
- ER图集成时要消除命名冲突以保证关系和属性名的唯一 ,在子模式设计时可以重新定义这些名称,以符合用户习 惯
- 给不同级别的用户定义不同的子模式,以保证系统安全性
- 产品(产品号,产品名,规格,单价,产品成本,产品合 格率)
- 为一般顾客建立子模式:产品1(产品号,产品名,规格,单价)
- 为销售部门建立:产品2(产品号,名称,规格,单价,成本,合 格率)
- 简化用户程序对系统的使用
- 可将某些复杂查询设计为子模式以方便使用
四、数据库物理设计
- 设计数据库的物理结构
- 为关系模式选择存取方法
- 设计数据库的存储结构
- 物理设计的考虑
- 查询时间效率
- 存储空间
- 维护代价
- 物理设计依赖于给定的计算机系统
选择存取方法
- 存取方法:数据的存取路径
- 例如图书查询
- 存取方法的选择目的是加快数据存取的速度
- 索引存取方法
- 聚簇存取方法
- 散列存取方法
设计存储结构
- 针对应用环境和DBMS特性,合理安排数据存储 位置
- 表和索引可考虑放在不同的磁盘上,使查询时可以并行 读取
- 日志文件和备份文件由于数据量大,而且只有恢复时使 用,可放到磁带上
- 确定系统配置
- 系统初始参数不一定适合应用并发用户数、同时打开的数据库对象数、缓冲区分配参 数、物理块的大小等
五、数据库实施

六、数据库维护
